Abstract
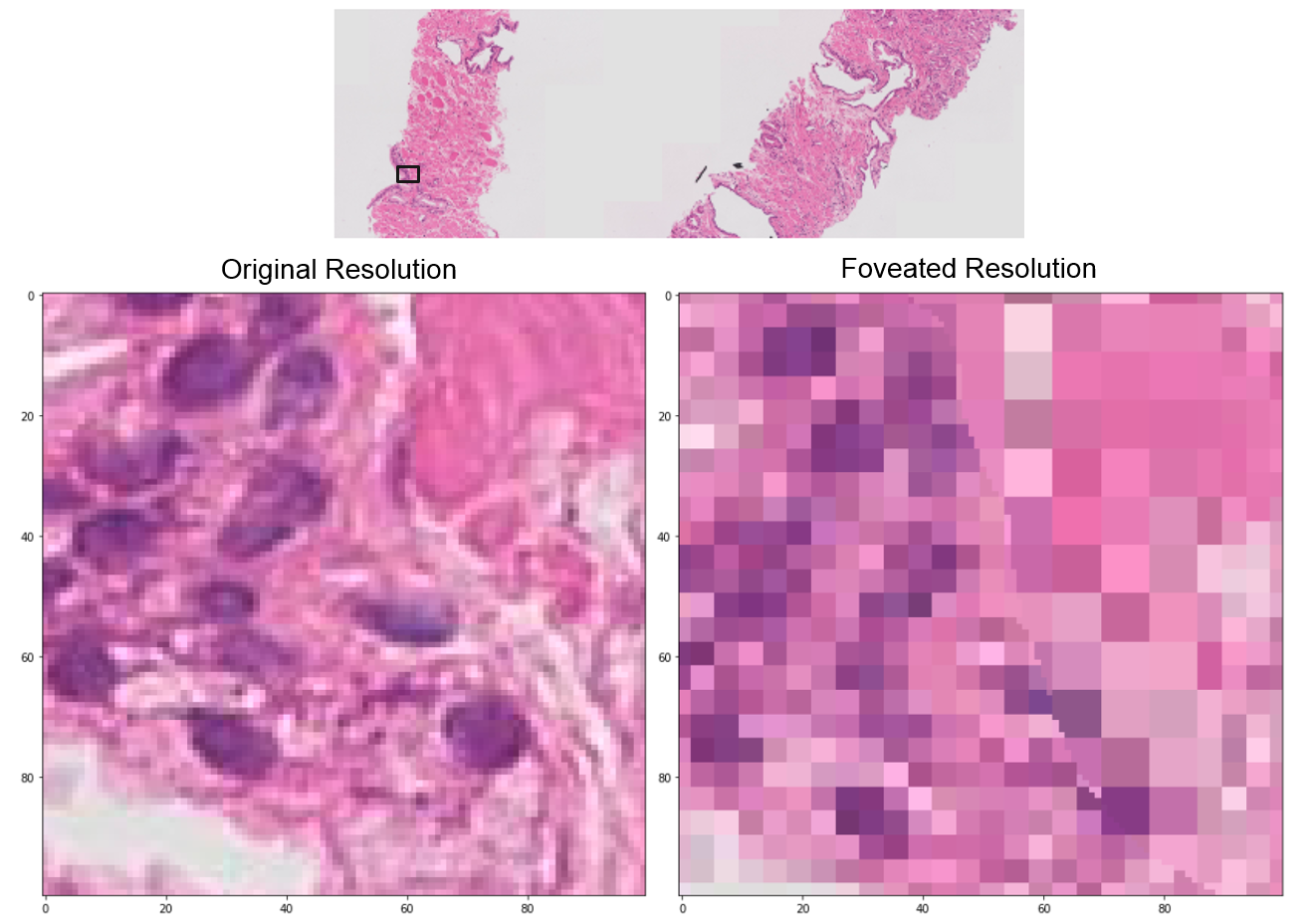
Segmentation of ultra-high resolution images is challenging because of their enormous size, consisting of millions or even billions of pixels. Typical solutions include dividing input images into patches of fixed size and/or down-sampling to meet memory constraints. Such operations incur information loss in the field-of-view (FoV) i.e., spatial coverage and the image resolution. The impact on segmentation performance is, however, as yet understudied. In this work, we start with a motivational experiment which demonstrates that the trade-off between FoV and resolution affects the segmentation performance on ultra-high resolution images—and furthermore, its influence also varies spatially according to the local patterns in different areas. We then introduce foveation module, a learnable “dataloader” which, for a given ultra-high resolution image, adaptively chooses the appropriate configuration (FoV/resolution trade-off) of the input patch to feed to the downstream segmentation model at each spatial location of the image. The foveation module is jointly trained with the segmentation network to maximise the task performance. We demonstrate on three publicly available high-resolution image datasets that the foveation module consistently improves segmentation performance over the cases trained with patches of fixed FoV/resolution trade-off. Our approach achieves the SoTA performance on the DeepGlobe aerial image dataset. On the Gleason2019 histopathology dataset, our model achieves better segmentation accuracy for the two most clinically important and ambiguous classes (Gleason Grade 3 and 4) than the top performers in the challenge by 13.1% and 7.5%, and improves on the average performance of 6 human experts by 6.5% and 7.5%. Our code and trained models are available at https://github.com/lxasqjc/Foveation-Segmentation.